
Remote sensing imagery provides comprehensive views of the Earth, where different sensors collect complementary data at different spatial scales. Large, pretrained models are commonly finetuned with imagery that is heavily augmented to mimic different conditions and scales, with the resulting models used for various tasks with imagery from a range of spatial scales. Such models overlook scale-specific information in the data. In this paper, we present Scale-MAE, a pretraining method that explicitly learns relationships between data at different, known scales throughout the pretraining process. Scale-MAE pretrains a network by masking an input image at a known input scale, where the area of the Earth covered by the image determines the scale of the ViT positional encoding, not the image resolution. Scale-MAE encodes the masked image with a standard ViT backbone, and then decodes the masked image through a bandpass filter to reconstruct low/high frequency images at lower/higher scales. We find that tasking the network with reconstructing both low/high frequency images leads to robust multiscale representations for remote sensing imagery. Scale-MAE achieves an average of a 5.0% non-parametric kNN classification improvement across eight remote sensing datasets compared to current state-of-the-art and obtains a 0.9 mIoU to 3.8 mIoU improvement on the SpaceNet building segmentation transfer task for a range of evaluation scales.
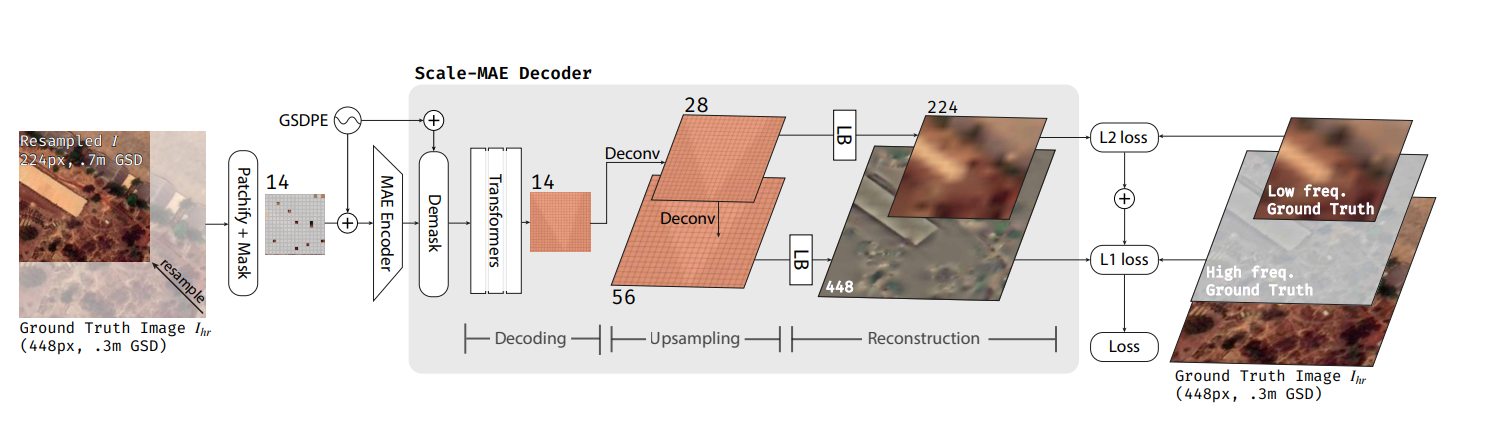
Scale-MAE has two key components: a Ground Sample Distance (GSD) based positional encoding and a multi-band Laplacian-pyramid decoder. Unlike typical positional encoding used in vision transformers, the GSD based positional encoding scales in proportion to the area of land in an image covers, regardless of the pixel resolution of the image. The wavelength of sinusoids, in terms of absolute groud distance, is invariant across multiple scales. The Laplacian-pyramid decoder reconstruct a laplician representation of the original image, where L1 loss is applied on high-frequency information and L2 loss is applied on low-frequency information. This construction explictly allows the model to learn represnetations of different frequency/scales.
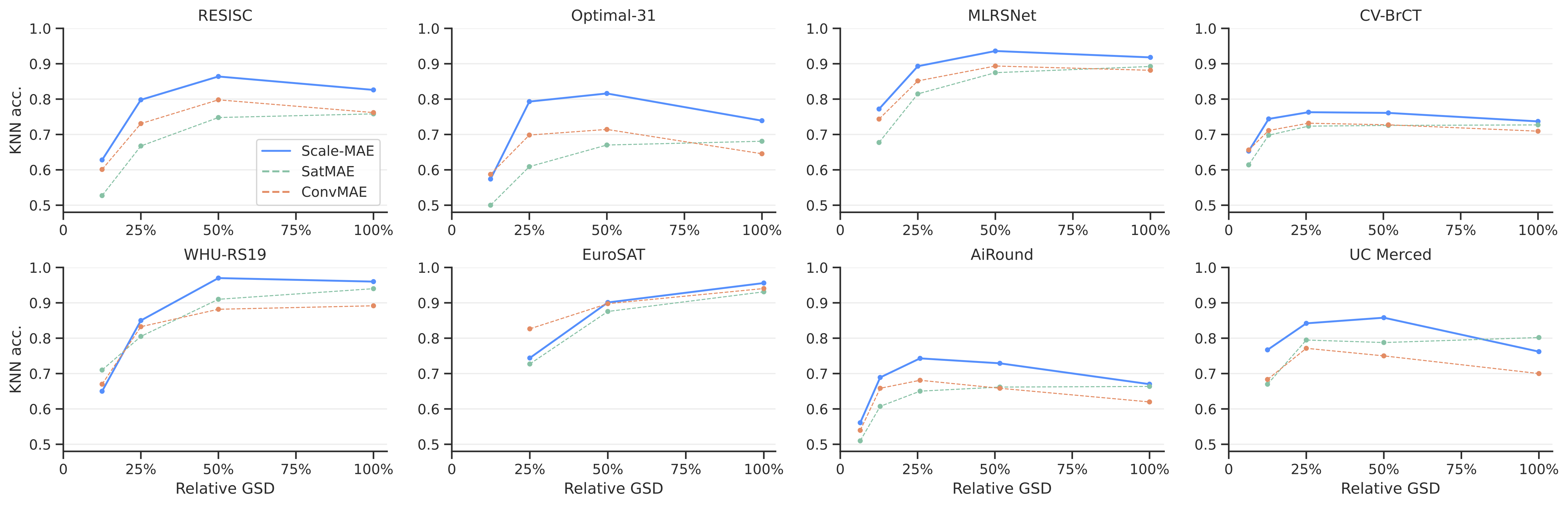
Compared to state-of-the-art remote sensing pre-training methods, Scale-MAE-based represeentations perform better for a kNN classification task on multiple remote sensing datasets. These datasets are collected from different platforms at different ground sample distances.

While Scale-MAE is not built with the goal of high-fidelity reconstruction, the reconstructions that our method does produce are convincing. Notably, the learned low and high frequency components are visually convincing.
There's a wonderful project called SatMAE that also pretrains models for geospatial imagery, particularly multi-modal spatiotemporal data -- check out that project if it fits your use case! Also, Scale-MAE and SatMAE should be able to be combined for multi-scale multi-modal spatiotemporal data, but we haven't tried it yet ourselves. Let us know if you do!
@InProceedings{ScaleMAE_2023_ICCV,
author = {Reed, Colorado J and Gupta, Ritwik and Li, Shufan and Brockman, Sarah and Funk, Christopher and Clipp, Brian and Keutzer, Kurt and Candido, Salvatore and Uyttendaele, Matt and Darrell, Trevor},
title = {Scale-MAE: A Scale-Aware Masked Autoencoder for Multiscale Geospatial Representation Learning},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {4088-4099}
}