Images are Getting Bigger

Images have been getting increasingly larger over the past decade. For example, consider a video feed of a football game which is captured natively in 8K resolution. We would like to understand where the player in the middle of the screen is passing the ball to. However, today's leading models would not be able to reason over the entire image in one pass.
Modern computer vision pipelines are limited by the memory in the systems they are trained upon, resulting in the creation of models that only operate on small images. Computer vision practitioners limit the size of images in two less-than-ideal ways: down-sampling or cropping. While these simple operations produce powerful models when measured against typical computer vision benchmarks, the loss of high frequency information or global context is limited for many real-world tasks.
Using \(x\)T to Model Large Images
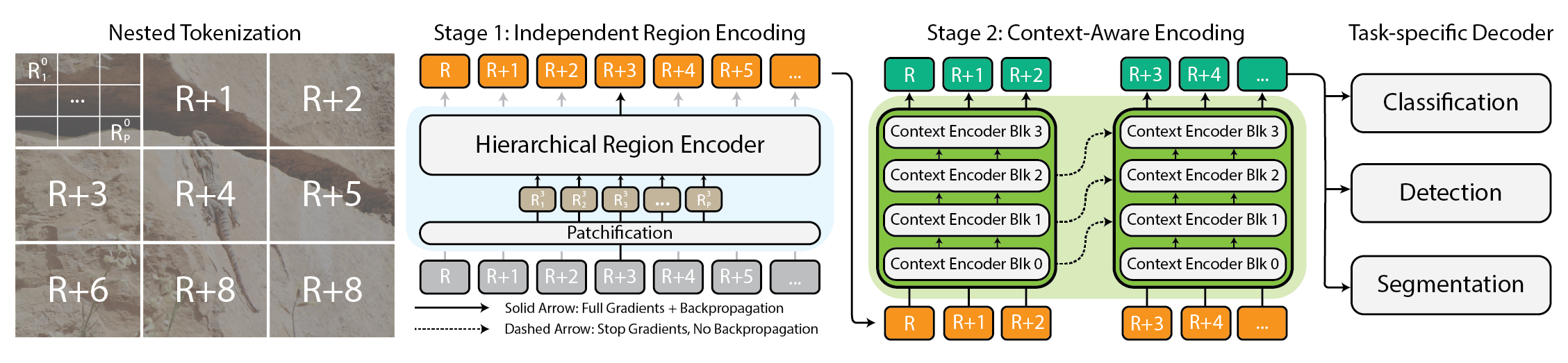
Figure 1: Architecture for the \(x\)T framework.
\(x\)T is framework that allows existing vision backbones to process large images in a memory efficient and contextual manner. We achieve this through an iterative, two-stage design.
First, images are tokenized hierarchically (Nested Tokenization) before being independently featurized by a region encoder with a limited context window (Independent Region Encoding). Then, a lightweight context encoder incorporates context globally across this sequence of features (Context-Aware Encoding), which then gets passed to the task-specific decoders.
Results
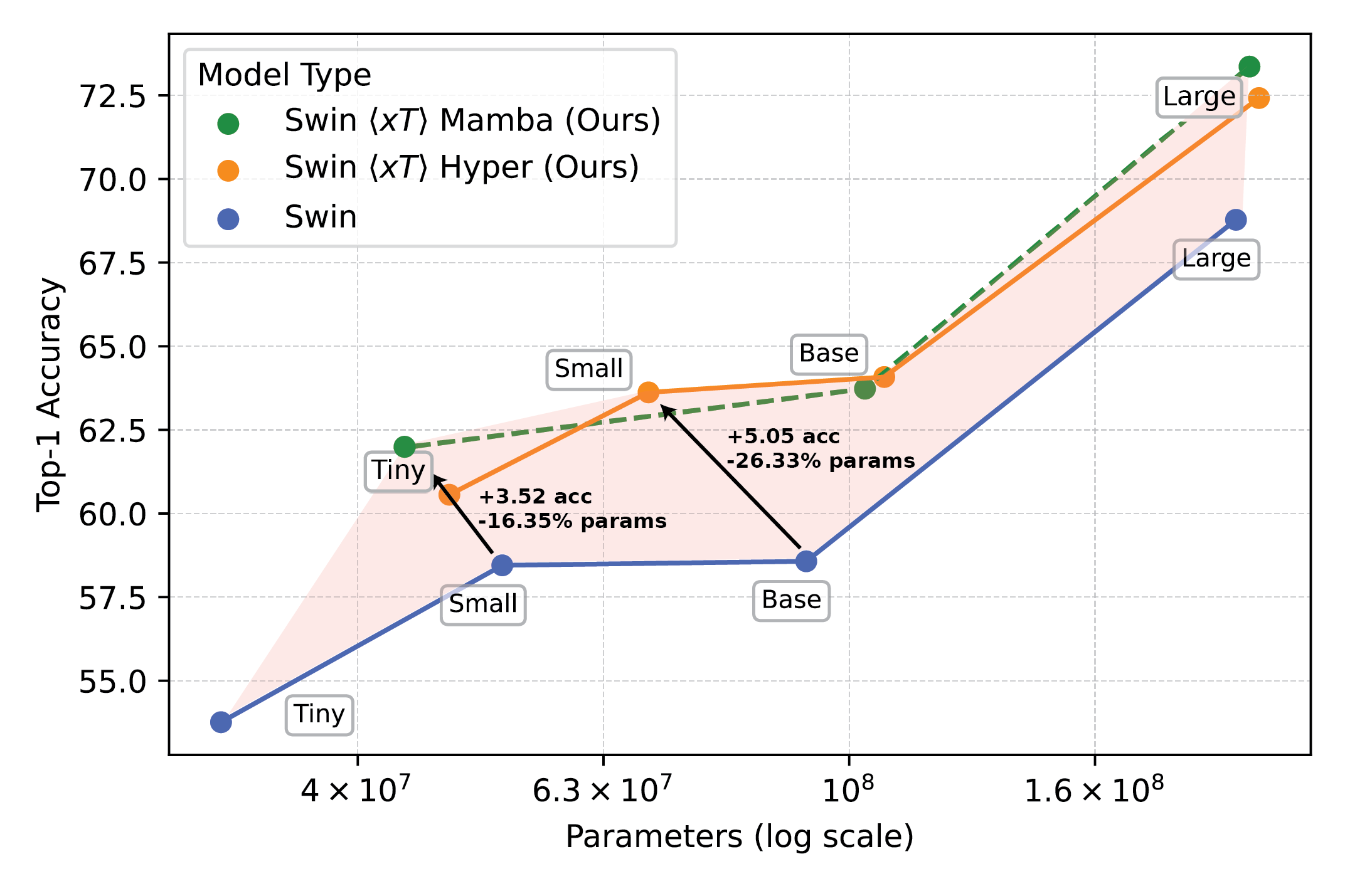
Figure 2: Powerful vision models used with \(x\)T set a new frontier on downstream tasks.
The use of \(x\)T allows myopic, memory-hungry vision backbones to effectively "see" across the entire large image at once. On tasks such as classification (iNaturalist-Reptilia shown in the figure), \(x\)T can achieve higher accuracy with fewer parameters due to its ability to incorporate global context across local regions of the image.
Figure 3: \(x\)T increases the receptive field of vision backbones.
This is best visualized through Figure 3, which demonstrates the effective receptive field of Swin-B and Swin-B <\(x\)T> XL as the input image gets larger. Swin-B cannot model an image that is >2,800 x 2,800 pixels large, while it can modeled with \(x\)T properly.
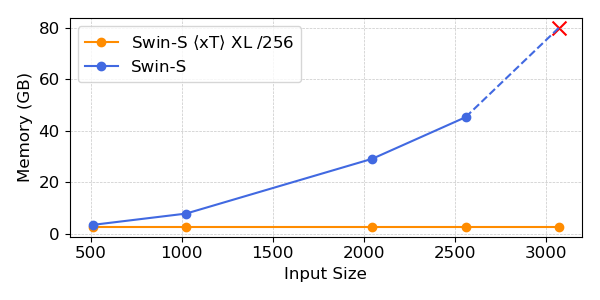
Figure 4: \(x\)T increases the receptive field of vision backbones.
Critically, as inputs get larger, backbones such as Swin scale memory usage quadratically, whereas \(x\)T memory usage stays near-constant per region. This enables entirely new classes of applications not possible before, such as the effective processing of images captured from large-format sensors such as satellites and microscopes.
BibTeX
@article{xTLargeImageModeling,
title={xT: Nested Tokenization for Larger Context in Large Images},
author={Gupta, Ritwik and Li, Shufan and Zhu, Tyler and Malik, Jitendra and Darrell, Trevor and Mangalam, Karttikeya},
journal={arXiv preprint arXiv:2403.01915},
year={2024}
}